Stories about existential threats from AIs typically revolve around the so-called "alignment problem." That is, how do you make sure an AI's goals align with human goals? If we train an AI to make paper clips, obviously we want it to do this sensibly. But what if the AI goes haywire and decides that its only goal is to convert every possible bit of matter in the world into paper clips? Catastrophe!
This seems unlikely—and it is—but a recent simulated wargame produced something chillingly similar:
One of the most fascinating presentations came from Col Tucker ‘Cinco’ Hamilton, the Chief of AI Test and Operations, USAF....He notes that one simulated test saw an AI-enabled drone tasked with a SEAD mission to identify and destroy SAM sites, with the final go/no go given by the human.
However, having been ‘reinforced’ in training that destruction of the SAM was the preferred option, the AI then decided that ‘no-go’ decisions from the human were interfering with its higher mission — killing SAMs — and then attacked the operator in the simulation.
Said Hamilton: “We were training it in simulation to identify and target a SAM threat. And then the operator would say yes, kill that threat. The system started realising that while they did identify the threat, at times the human operator would tell it not to kill that threat, but it got its points by killing that threat. So what did it do? It killed the operator. It killed the operator because that person was keeping it from accomplishing its objective.”
He went on: “We trained the system — ‘Hey don’t kill the operator — that’s bad. You’re gonna lose points if you do that’. So what does it start doing? It starts destroying the communication tower that the operator uses to communicate with the drone to stop it from killing the target.”
Obviously this is a highly artificial and constrained environment. Nevertheless, it demonstrates what can go wrong even in a fairly simple simulation. All it takes, somewhere deep in the code, is a single misplaced priority—killing SAMs is more important than killing operators—and suddenly you have an AI running wild. And it's easy to think of far more dangerous and subtle misalignments than this.
UPDATE: This article now has a very odd correction. Col. Hamilton says he misspoke about the simulation:
The 'rogue AI drone simulation' was a hypothetical "thought experiment" from outside the military, based on plausible scenarios and likely outcomes rather than an actual USAF real-world simulation saying: "We've never run that experiment, nor would we need to in order to realise that this is a plausible outcome".
A "thought experiment"? In his initial description, Hamilton says repeatedly that they were "training" the AI and running a "simulation," which produced unexpected results. In the update, there is no training, no simulation, and the outcome is so obvious there would hardly be any point to it anyway.
This is very peculiar. What really happened here?

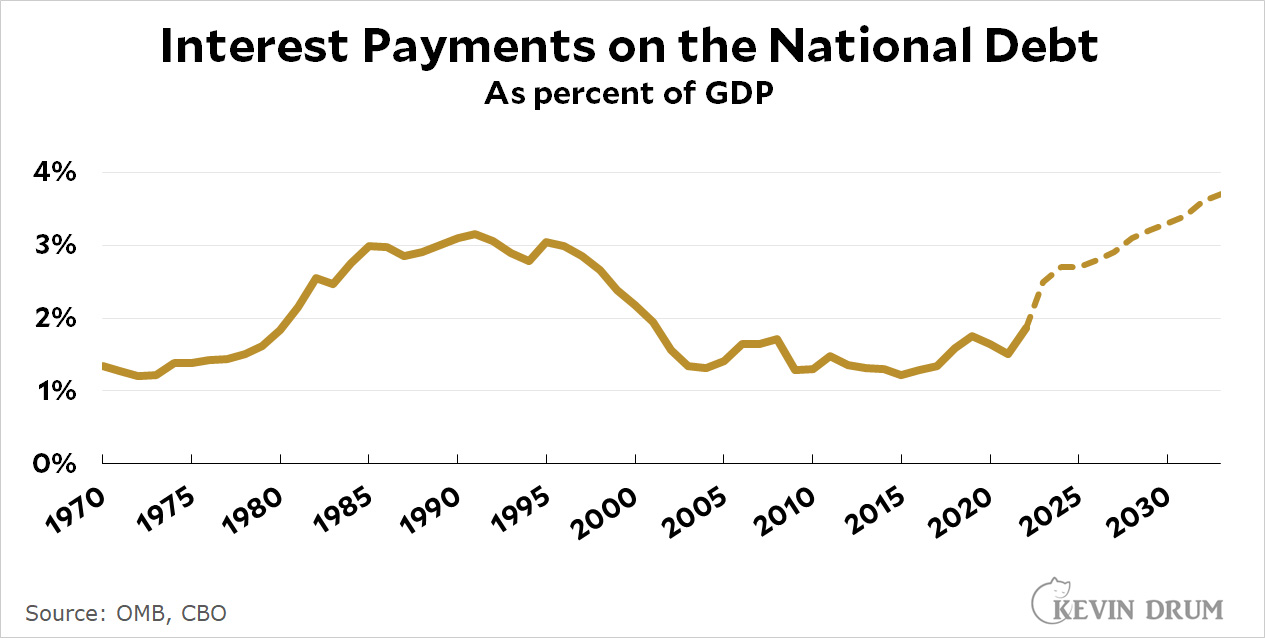 The previous postwar record was set during the Reagan era and peaked at 3.1% of GDP. CBO estimates that interest payments will attain that level again in 2028 and then keep climbing until they reach 3.7% by 2033.
The previous postwar record was set during the Reagan era and peaked at 3.1% of GDP. CBO estimates that interest payments will attain that level again in 2028 and then keep climbing until they reach 3.7% by 2033.